Cribl puts your IT and Security data at the center of your data management strategy and provides a one-stop shop for analyzing, collecting, processing, and routing it all at any scale. Try the Cribl suite of products and start building your data engine today!
Evolving demands placed on IT and Security teams are driving a new architecture for how observability data is captured, curated, and queried. This new architecture provides flexibility and control while managing the costs of increasing data volumes.
Cribl Stream is a vendor-agnostic observability pipeline that gives you the flexibility to collect, reduce, enrich, normalize, and route data from any source to any destination within your existing data infrastructure.
Cribl Lake is a turnkey data lake solution that takes just minutes to get up and running — no data expertise needed. Leverage open formats, unified security with rich access controls, and central access to all IT and security data.
Cribl’s leadership team has built and launched category-defining products for some of the most innovative companies in the technology sector, and is supported by the world’s most elite investors.
Whether you’re just getting started or scaling up, the Cribl for Startups program gives you the tools and resources your company needs to be successful at every stage.
With Aggregations in Cribl LogStream 1.6, you can send your logs directly to Cribl and shape, extract, filter, drop, and now, aggregate! This new, powerful capability allows users to easily transform logs into metrics while running real-time, tumbling window aggregate functions on them.
In this post I would like to share various engineering problems/challenges we had to overcome in order to deliver a performant streaming aggregation system.
We had to determine how to:
handle various speed data streams
we don’t want to flush out buckets just because the data is coming in too slow, so we need to take in account the various speeds at which data can stream in to the aggregator.
handle concurrent historical and current data streams
we need to ensure that rules are in place to have all data regardless of event times are treated equally, so we don’t get lopsided aggregations with multiple buckets with one event for the same time range.
optimize memory
we’re aggregating an unbounded number of events (potentially across multiple instances of the aggregator function), so we need to make sure we don’t eat up all the RAM in the system.
I Ain’t Got Nothin’ but Time…Based Flushing
Cribl LogStream has two different types of streaming aggregation: cumulative and time-bucketed. We’ll discuss the time-bucketed streaming aggregations as they’re much more interesting from an engineering perspective.
To quickly summarize cumulative streaming aggregations, we essentially keep the running total of all the aggregates to output, and we dump out the current value every n seconds where n is the customer specified time span. Pretty simple stuff there.
Now to the main event…
As you will come to learn, one of my main principles of engineering is “you can’t optimize something that doesn’t exist.” We’ll follow that approach here while building out the time-bucketed streaming aggregations. First things first, let’s get something functional.
Step 1: One Stream, Two Stream, Old Stream, New Stream
As the heading of this section suggests, right now, we don’t care about the properties of the streams of data coming in to the aggregator. We just need to make sure that we put everything into the correct time bucket and flush out events.
The easiest way to do this, is to have a map of buckets that we can look up by their earliest event time. If a bucket doesn’t exist, just create a new one and put it in the map.
Very inefficiently, we need to walk all the entries in the map and check the latest times of all the buckets to see which ones can/should be flushed. In the current implementation, we also just do this check every time we receive a new event. This leaves us with a huge problem. If a data stream is slow, we could end up with events sitting in the aggregator waiting to be flushed, but no event is coming along to flush the aggregated event out in a timely manner.
Since aggregations are in the context of a pipeline, and good software design tells us that all the pieces within a framework should be decoupled, we can’t just call setTimeout in time-window-seconds. We have to work within the framework or update the framework.
Step 2: One Small Step for Aggregations, One Giant Leap for Framework Kind
Doing the right thing is usually the right thing to do, so we decided to update the framework at this point to enable primitive signals that can be sent to aggregations. This allows the aggregations to run within the context of the framework (i.e. no need to call setTimeout arbitrarily). The framework essentially heartbeats the aggregations function every second, and the aggregator will flush out any buckets that have a latest event time earlier than now(). This flushing mechanism also allows the framework to signal to aggregations to perform a “final flush” where we can dump out all of the time buckets that have been built up, so we don’t lose any data upon config change or shutdowns.
With periodic flushing built into the framework, we now have a “functional” time bucketing solution; however, as mentioned in the previous step, we have to perform inefficient walks over a map, and we still haven’t addressed what to do in the case that we’re getting historic data streams (meaning time buckets that will always be earlier than the now() cursor).
Step 3: The Bucket Data Structures They Are A-Changin’
Let’s stop and think about some properties of streams for a moment to determine exactly what we should do moving forward to address the issues mentioned in the previous section.
The most common data stream should be one made up of current data. This means all the data in the stream will have event times approximately equal to now(). This should be the hot path for our code/data structures.
The edge cases for data streams will be historic streams and/or slow streams. Historic streams are the opposite of our common case, where data has event times that are in the past. Slow streams are exactly what they sound like; they are streams where the events slowly trickle in over time.
This informs our design to optimize for new events with event times approximately equal to now() and to ensure that we can efficiently remove buckets when now() surpasses a bucket’s latest event time boundary. We should then have a data structure that handles buckets for historic streams as there really isn’t any heuristic we can pick on how those will show up over time whereas new data should always be around now() and strictly increasing in time.
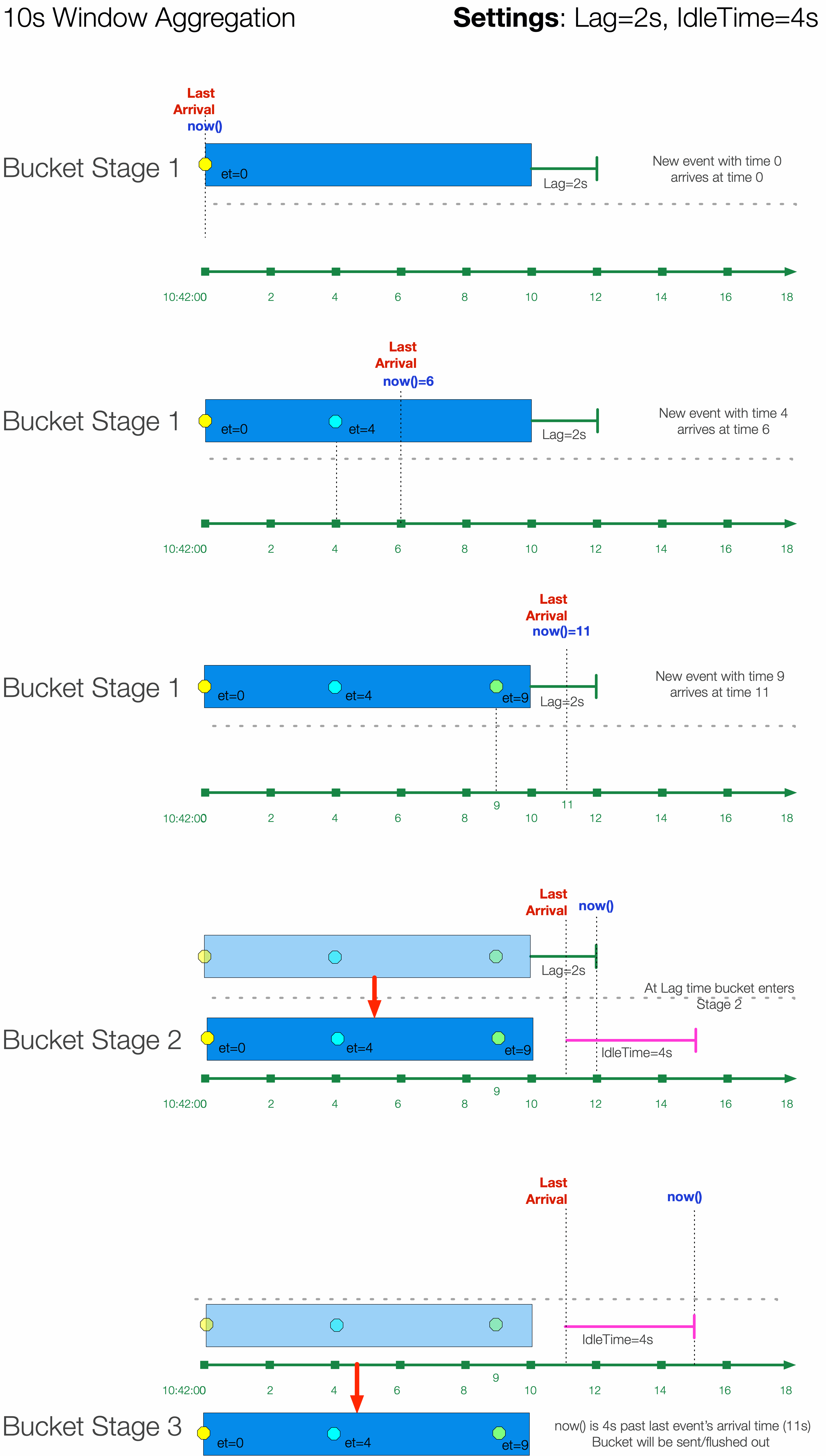
These new data structures help us optimize for contemporary data; however, we still face the problem of historic streams. Once a time bucket’s latest event time boundary is older than now(), should we just flush it out and render it to an event? We’d argue no. First, we need to handle the case of an event arriving late to a time bucket. If the latest time boundary of a bucket is t=10 and an event arrives with event_time=9, but it arrives at t=11, we would want that event to be placed in that time bucket before the bucket is flushed out. This is when we decided to add a configurable lag tolerance into aggregations. This way, we can wait n number of seconds past the time bucket latest event boundary for any late arriving events. This gives us better aggregation accuracy as events will be more accurately grouped together.
Now that contemporary data is being handled correctly, we need to take a look at how to handle historic data. If data comes in at t=0 and now()=30 (bucket time window is 10s), that means this bucket will have a latest event time boundary of 10. This event will flush instantly since the bucket falls behind now(). We could update the lag time to be huge, but that would lead to all buckets being delayed by a lot. Our solution to this problem is to introduce a bucket idle time. This setting makes sure that we don’t flush out a bucket unless no events have arrived for the idle time. In the above example, if we set the idle time to 1s, we won’t flush out the historic bucket until it has not received any events for 1s, so if events continuously are being sent to this time bucket, we’ll keep it open for writing. This keeps us from flushing out singular events, and we actually end up with much more accurate aggregations.
Now with these two settings, we introduce multiple stages of time buckets:
Stage
Writable
Description
1
Yes
Bucket consists of contemporary data. Bucket progresses to next stage via event time falling behind now()
2
Yes
Bucket consists of historic data. Bucket progresses to next stage if no events arrive for idle time limit
3
No
Bucket is flushed out and rendered to an event
Here is a diagram showing the lifecycle of a time bucket within the aggregation system:
Takeaways
Anything dealing with time is going to be complex. The key to a successful time-based feature is to introduce/expose as little complexity to the customer as possible. We could have gone so many different routes with a plethora of configurations to handle all sorts of exceptional data streams, but that would have made aggregations a convoluted mess and impossible to fully understand for any customer (or even future Cribl engineers). The best solution is usually the simplest and not over engineered. We examined what the main customer use case for aggregations would be, and we optimized the solution for that. Our minimalistic approach to configuration options empowers customers to better handle any exceptional data streams while lowering the barrier of entry for anyone trying to get setup for the first time.